From Symbolic Logic to Generative Intelligence
The history of Artificial Intelligence is not a linear progression but a series of “winters” and “springs”—periods of stagnation followed by explosive breakthroughs. For an introduction to modern AI, see the What Are Large Language Models guide.
We are currently living through the most significant acceleration in the field’s history.
The journey from Deep Blue’s chess victory in 1997 to ChatGPT’s conversational abilities in 2022 represents a fundamental shift in computing: from symbolic AI (systems based on explicit rules) to connectionist AI (systems that learn from data). Understanding this evolution is crucial for grasping where the technology is heading.
This retrospective analyzes the major milestones that brought us to the generative age: e-hour meeting into actionable items. These systems don’t just do things—they understand context, reason through problems, and adapt to my needs.
What happened in those 28 years? How did we go from a chess program that couldn’t chat to AI that passes bar exams, writes poetry, and helps scientists discover new medicines?
That’s the story I want to tell you today—the complete evolution of artificial intelligence, from its philosophical origins to the multimodal marvels of 2025.
75
Years of AI Evolution
2017
Transformer Breakthrough
25,000×
GPT-1 to GPT-5 Growth
5
Major AI Winters Survived
What You’ll Learn
By the end of this article, you’ll understand:
- The three distinct eras of AI development and what made each one unique
- Why early AI approaches hit a wall—and what we learned from those failures
- The breakthrough that changed everything: the Transformer architecture (2017)
- The complete GPT lineage—from GPT-1’s modest 117 million parameters to GPT-5’s trillions
- Where the major players came from: OpenAI, Anthropic, Google DeepMind, Meta
- What’s likely coming next—and why the pace is accelerating
Let’s start with the big picture. For detailed training insights, see the How LLMs Are Trained guide.
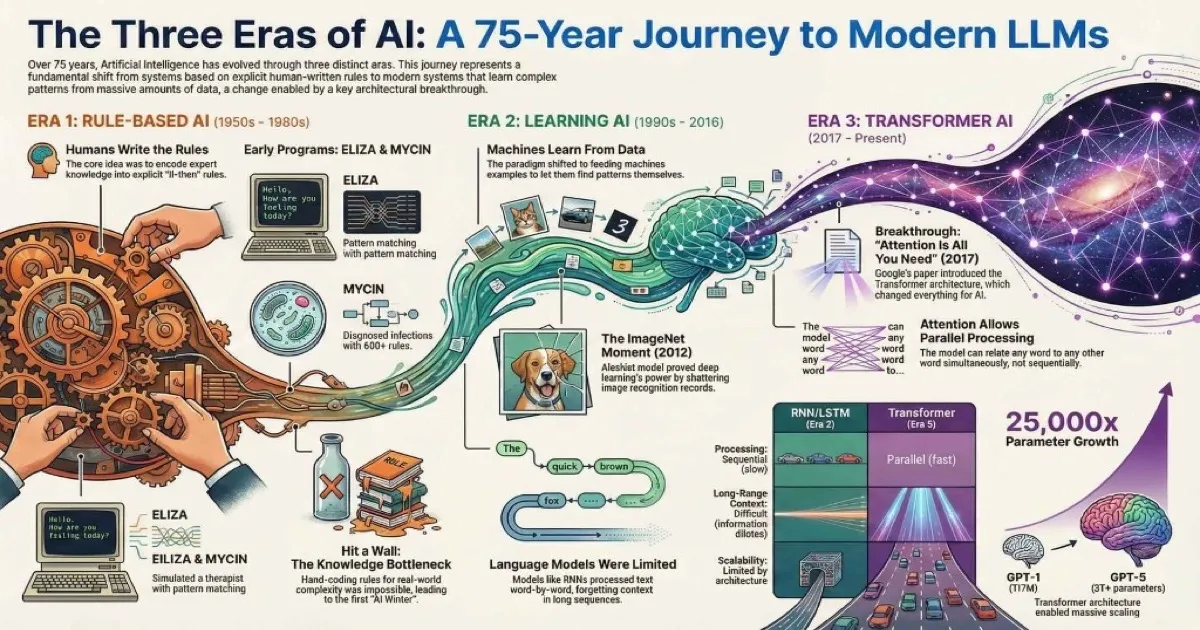
The Three Eras of Artificial Intelligence
I find it helpful to think of AI history as three distinct eras, each with its own philosophy about how to create intelligent machines:
The Three Eras of Artificial Intelligence
75 years of evolution in three distinct phases
Rule-Based AI
1950s-1980s
Humans write explicit rules
Learning AI
1990s-2016
Machines learn from data
Transformer AI
2017-Present
Attention changes everything
Era 1: Rule-Based AI (1950s-1980s) — Humans write the rules. If we can just encode enough expert knowledge, machines will be intelligent.
Era 2: Learning AI (1990s-2016) — Machines learn from data. Feed them enough examples and they’ll figure out the patterns themselves.
Era 3: Transformer AI (2017-Present) — Attention changes everything. The right architecture + massive scale = emergent intelligence. For understanding today’s AI landscape, see the Understanding the AI Landscape guide.
Each era built on the failures and insights of the previous one. Let’s dive into each.
Era 1: The Age of Rules (1950s-1980s)
The Birth of a Dream
The dream of artificial intelligence is older than computers themselves. But the field officially began at a summer workshop at Dartmouth College in 1956.
The key figures gathered there:
- John McCarthy (who coined the term “Artificial Intelligence”)
- Marvin Minsky (father of neural networks)
- Claude Shannon (father of information theory)
- Herbert Simon (Nobel laureate, cognitive scientist)
Their proposal was audacious:
“We propose that a 2 month, 10 man study of artificial intelligence be carried out… The study is to proceed on the basis of the conjecture that every aspect of learning or any other feature of intelligence can in principle be so precisely described that a machine can be made to simulate it.”
They thought AI would be solved within a generation. They were… optimistic.
The First AI Programs
Before we had ChatGPT, we had ELIZA.
ELIZA (1966) was created by Joseph Weizenbaum at MIT to simulate a psychotherapist. It worked through simple pattern matching:
User: "I'm feeling sad today."
ELIZA: "Tell me more about your feelings."
User: "My mother doesn't understand me."
ELIZA: "Tell me more about your mother."The trick was simple: find keywords (“mother”, “feeling”) and respond with pre-written patterns. There was no understanding—just clever text manipulation.
The surprising part? People formed genuine emotional connections with ELIZA. They knew it was a program, yet they still confided in it. This taught researchers something important about how humans anthropomorphize machines—a lesson we’re still learning with modern chatbots.
SHRDLU (1971) was more impressive. Terry Winograd created a program that could understand complex commands about a virtual world of colored blocks:
“Put the red block on top of the blue pyramid, then put the green block next to the red block.”
SHRDLU could parse these sentences, understand spatial relationships, and execute the commands correctly. It worked perfectly—in a tiny, controlled universe of blocks. The real world was infinitely messier.
Expert Systems: The First AI Boom
By the late 1970s, researchers shifted to a new approach: expert systems. The idea was simple—encode the knowledge of human experts as rules.
MYCIN (1970s) was a medical diagnosis system for blood infections:
- 600+ rules written by human doctors
- IF patient has symptom X AND symptom Y THEN consider disease Z
- Actually outperformed junior doctors in blind tests
For a moment, it seemed like this was the path to AI. Companies invested billions. The “expert systems” market boomed.
But there was a fundamental problem: the knowledge bottleneck.
| Expert System | Domain | Rules Required | Problem |
|---|---|---|---|
| MYCIN | Blood infections | 600+ | Couldn’t explain reasoning |
| XCON/R1 | Computer configuration | 2,500+ | Maintenance nightmare |
| CYC | Common sense knowledge | 10,000,000+ | Never-ending project |
Every edge case needed a new rule. Real-world complexity was infinite. Hand-coding human knowledge was a losing game.
The First AI Winter
By the mid-1970s, the hype had outpaced the reality. Key failures emerged:
- The Perceptron Problem (1969): Minsky and Papert published a book showing that single-layer neural networks couldn’t learn simple patterns (like XOR). This crushed interest in neural networks for nearly two decades.
- Expert System Brittleness: These systems broke in unexpected ways. They couldn’t handle situations outside their narrow expertise.
- DARPA Funding Cuts: The US government, disappointed by unmet promises, slashed AI research funding.
The lesson learned: You can’t hand-code intelligence. The world is too complex, too nuanced, too messy. Somehow, machines would need to learn for themselves.
💡 Historical Insight: This first AI winter lasted from roughly 1974 to 1980. It taught the field a crucial lesson about overpromising—a lesson that remains relevant as we navigate the current AI boom.
Era 2: The Age of Learning (1990s-2016)
The Neural Network Comeback
Neural networks—inspired by the brain’s architecture—had been largely abandoned after the perceptron critique. But a few researchers kept the faith.
Backpropagation Rediscovered (1986)
The key breakthrough came from Rumelhart, Hinton, and Williams. They popularized backpropagation—an algorithm that lets neural networks learn from their mistakes.
Here’s the intuition:
- Network makes a prediction
- Compare prediction to correct answer
- Calculate the error
- Propagate that error backwards through the network
- Adjust each connection slightly to reduce the error
- Repeat millions of times
With backpropagation, networks with multiple layers became trainable. But computing power wasn’t there yet.
The Machine Learning Era
Through the 1990s and 2000s, machine learning evolved with techniques that didn’t require massive computation:
- Support Vector Machines: Found optimal boundaries between categories
- Random Forests: Combined many decision trees for robust predictions
- Gradient Boosting: Iteratively improved predictions
These methods powered the first wave of practical AI:
- Spam filters that learned from labeled emails
- Recommendation systems that learned from user behavior
- Fraud detection that learned from transaction patterns
But for language and vision—the domains that feel intelligent—progress was slower.
The ImageNet Moment (2012)
Everything changed on September 30, 2012.
That’s when Geoffrey Hinton’s team entered AlexNet into the ImageNet image classification competition—and obliterated the competition.
| Year | Best Error Rate | Method |
|---|---|---|
| 2010 | 28.2% | Traditional computer vision |
| 2011 | 25.8% | Improved traditional |
| 2012 | 15.3% | AlexNet (deep learning) |
The gap was stunning. AlexNet used:
- Deep neural networks (8 layers)
- GPU computing (parallelized on Nvidia chips)
- ReLU activations (faster training)
- Dropout (prevented overfitting)
This was the moment deep learning became undeniable. Investment flooded in. The race was on.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart LR
A["ImageNet 2012"] --> B["Deep Learning Proven"]
B --> C["GPU Computing"]
B --> D["Massive Investment"]
C --> E["Faster Training"]
D --> E
E --> F["Transformer Era"]Language AI Before Transformers
For language, progress came more slowly. The main architectures were Recurrent Neural Networks (RNNs) and their improved variant, LSTMs.
Word2Vec (2013) was a breakthrough in representing meaning. It discovered that words could be represented as vectors in space, with meaningful relationships:
king - man + woman = queen
This was revolutionary—mathematics could capture semantic meaning!
But RNNs had a fundamental limitation: they processed text sequentially, one word at a time. Information about early words had to survive through every subsequent word—and it often didn’t.
| Challenge | RNN Behavior |
|---|---|
| ”The cat that lived in the house that Jack built was happy” | By the time we reach “happy”, the model has partially forgotten “cat” |
| Long documents | Earlier content gets “diluted” |
| Training speed | Can’t parallelize—must process word by word |
Something better was needed.
Era 3: The Transformer Revolution (2017-Present)
“Attention Is All You Need”
On June 12, 2017, a team of eight researchers at Google published a paper with an almost playful title: “Attention Is All You Need.”
This paper introduced the Transformer architecture, and it changed everything.
The core innovation was the attention mechanism—a way for the model to directly relate any word to any other word, regardless of their distance in the text.
Why Transformers Won
RNN/LSTM vs Transformer architecture comparison
Processing
Sequential (slow)
Parallel (fast)
Long-range Dependencies
Difficult (info dilutes)
Excellent (direct attention)
Training Speed
Slow (sequential)
Fast (parallelizable)
Scalability
Limited by architecture
Scales with compute
Memory Usage
Efficient (constant)
Quadratic with length
💡 The Game Changer: Transformers process all words simultaneously, allowing them to understand relationships between any two words directly—no matter how far apart they are in the text.
Sources: Attention Is All You Need • The Illustrated Transformer
How Attention Works (The Intuition)
Imagine you’re reading a novel and someone asks you: “Who does ‘she’ refer to in paragraph three?”
You don’t read the entire book from the beginning. You go back to paragraph three, find “she,” and scan the surrounding context for female characters. You’re attending to specific, relevant parts of the text.
That’s what the attention mechanism does:
Example: “The animal didn’t cross the street because it was too tired.”
- What does “it” refer to?
- The model attends to all other words simultaneously
- It learns that “it” has high attention to “animal” (context: “tired”)
- And low attention to “street” (streets don’t get tired)
Key insight: Every word can directly attend to every other word. No more information bottleneck. Process the entire sequence in parallel.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart TB
A["Input: 'The animal didn't cross the street because it was tired'"]
A --> B["Tokenization"]
B --> C["Embeddings + Position Encoding"]
C --> D["Self-Attention Layers"]
D --> E["'it' attends to 'animal' with high weight"]
D --> F["'it' attends to 'street' with low weight"]
E --> G["Feed-Forward Layers"]
F --> G
G --> H["Output: Understanding 'it' = 'animal'"]The Transformer Architecture
The full Transformer has two main parts:
- Encoder: Understands input (used for tasks like classification, translation)
- Decoder: Generates output (used for text generation)
GPT-style models use only the decoder (they generate text). BERT-style models use only the encoder (they understand text).
Key components:
- Self-attention layers — Relate words to each other
- Feed-forward layers — Process information
- Position encodings — Track word order (since attention is position-agnostic)
- Layer normalization — Stabilize training
- Residual connections — Help gradient flow in deep networks
BERT: The Bidirectional Breakthrough (2018)
A year after the Transformer paper, Google released BERT (Bidirectional Encoder Representations from Transformers).
BERT’s innovation was reading text in both directions simultaneously:
- “The cat sat on the ___” → What comes next?
- ”___ cat sat on the mat” → What came before?
This bidirectional understanding transformed Google Search overnight. Suddenly, the search engine could understand nuanced queries instead of just matching keywords.
BERT’s legacy: It proved the pre-training + fine-tuning paradigm. Train on massive unlabeled data first, then fine-tune for specific tasks. This became the standard approach for all modern LLMs. For a comprehensive guide to fine-tuning techniques, see the Fine-Tuning and Customizing LLMs guide.
The GPT Lineage: From Experiment to Phenomenon
While Google focused on BERT, a small research lab in San Francisco was betting on a different approach.
The OpenAI Origin Story
December 2015: Sam Altman, Elon Musk, and others founded OpenAI with a $1 billion pledge. The mission: ensure AI benefits all of humanity.
The bet was ambitious: scale + compute + Transformers = intelligence. Many were skeptical. After all, bigger isn’t always better, right?
Key researchers who joined: Ilya Sutskever (co-founder), Alec Radford (GPT architect), Dario Amodei (later founded Anthropic).
GPT-1: Proof of Concept (June 2018)
The first GPT was modest by today’s standards:
- Parameters: 117 million
- Training data: BooksCorpus (7,000 books)
- Context window: 512 tokens (~400 words)
- Key insight: Pre-train on massive text, then fine-tune for tasks
Reception: “Interesting research paper.” Nobody predicted what came next.
GPT-2: “Too Dangerous to Release” (February 2019)
GPT-2 was 12× larger—1.5 billion parameters—and trained on 8 million web pages.
The results were concerning. Give it a prompt like “A fire broke out in downtown San Francisco yesterday…” and it would generate multiple paragraphs of eerily realistic fake news.
OpenAI initially withheld the full model, fearing misuse for disinformation. This sparked the first major debate about AI safety and responsible release. For more on AI safety considerations, see the Understanding AI Safety, Ethics, and Limitations guide.
The capabilities:
- Coherent multi-paragraph text
- Story continuation
- Basic code generation
- Style mimicry
Reception: “This is getting scary good.”
GPT-3: The World Takes Notice (June 2020)
Then came GPT-3, and everything changed.
The scale:
- 175 billion parameters (100× GPT-2)
- 570 GB of training text
- Estimated $4.6 million training cost
- Trained on 314 Nvidia V100 GPUs
The breakthrough capability: Few-shot learning.
You could give GPT-3 just a few examples of a task, and it would generalize:
Translate English to French:
sea otter => loutre de mer
peppermint => menthe poivrée
cheese =>GPT-3: fromage
Nobody explicitly taught it French. It learned the pattern from examples.
The demos that went viral:
- Writing essays indistinguishable from humans
- Generating working code from plain descriptions
- Having philosophical conversations
- Creating original poetry in various styles
API launch: For the first time, the public could access a frontier LLM. Thousands of startups were born overnight.
The GPT Lineage: 6 Years of Exponential Growth
From 117M to 3+ trillion parameters
🚀 Key Insight: GPT-5.2 has approximately 25,000× more parameters than GPT-1. Context windows grew from 512 tokens (~400 words) to 256K tokens (~200,000 words).
Sources: OpenAI Papers • Wikipedia - GPT • OpenAI Blog
ChatGPT: AI Goes Mainstream (November 2022)
ChatGPT wasn’t actually a new model—it was GPT-3.5 with conversational fine-tuning using a technique called RLHF (Reinforcement Learning from Human Feedback). For a detailed explanation of RLHF and training techniques, see the How LLMs Are Trained guide.
The magic of RLHF:
- Have humans rank model responses (which is more helpful?)
- Train a “reward model” to predict human preferences
- Optimize the LLM to maximize that reward
This made ChatGPT:
- More helpful and conversational
- Less likely to produce harmful content
- Better at following instructions
- Feel like talking to a smart assistant
The adoption numbers were unprecedented:
- 1 million users in 5 days (Netflix: 3.5 years)
- 100 million monthly users in 2 months
- The fastest-growing consumer application in history
ChatGPT wasn’t just a product—it was a cultural moment. Suddenly everyone from students to CEOs was using AI daily. For a comparison of modern AI assistants, see the AI Assistants Comparison guide.
GPT-4: The Leap to Multimodal (March 2023)
GPT-4 was the jump that proved LLMs weren’t a one-time trick:
- Parameters: Estimated 1.8 trillion (Mixture of Experts architecture)
- Vision capabilities: Could understand and reason about images
- Context window: 8K → 32K → 128K tokens
- Reasoning: Dramatic improvement in complex multi-step problems
For more on tokens and context windows, see the Tokens, Context Windows & Parameters guide.
Benchmark domination:
- Passed the bar exam (top 10%)
- SAT: 1,400+/1,600
- GRE: Near-perfect verbal
- AP exams: 5s across subjects
GPT-4 made multimodal AI the new standard. An LLM that couldn’t see images suddenly felt incomplete.
GPT-5.2 & o3: The Reasoning Era (2024-2025)
September 2024: OpenAI releases o1, a new kind of model—a “reasoning model” that thinks before answering.
Unlike previous GPTs that immediately generate responses, o1 uses chain-of-thought reasoning internally:
- Breaks problems into steps
- Considers multiple approaches
- Checks its own work
- Can solve complex math and science problems
December 2025: Two major releases:
GPT-5.2 arrives in three versions:
- Instant — Fast responses for quick tasks
- Thinking — Takes more time, better reasoning
- Pro — Maximum capability for complex work
o3 and o3-Pro push reasoning further:
- Near-expert performance on science benchmarks
- Autonomous tool use (web search, Python, image generation)
- Multi-step planning and execution
The pattern continues: each generation roughly 10× more capable.
The Competitive Landscape
OpenAI isn’t alone at the frontier. Let’s meet the other major players.
The AI Company Landscape (December 2025)
Major players from open source to closed commercial
OpenAI
ClosedAnthropic
ClosedGoogle DeepMind
Mostly ClosedMeta AI
Open SourceDeepSeek
Open WeightOpen Source ↔ Closed Spectrum
Sources: Company Websites • TechCrunch • The Information
Anthropic and the Claude Family
Founded (2021) by Dario and Daniela Amodei—former OpenAI researchers who left to focus on AI safety.
Their approach: Constitutional AI. Instead of just using human feedback, they train Claude with explicit rules about being helpful, harmless, and honest.
The Claude Evolution:
| Model | Release | Key Advance |
|---|---|---|
| Claude 1 | March 2023 | Competitor emerges |
| Claude 2 | July 2023 | 100K context (groundbreaking) |
| Claude 3 | March 2024 | Opus/Sonnet/Haiku tiers |
| Claude 3.5 Sonnet | June 2024 | New benchmark leader |
| Claude Opus 4.5 | November 2025 | World’s best coding model |
What makes Claude different:
- More nuanced, careful responses
- Better at acknowledging uncertainty
- Computer use capabilities (can control browsers)
- Excellent for long documents and coding
Google DeepMind & the Gemini Family
Google actually has the longest AI heritage:
- DeepMind (founded 2010, acquired 2014): Created AlphaGo, AlphaFold
- Google Brain (started 2011): Pioneered many deep learning techniques
In 2023, these groups merged into Google DeepMind.
The Gemini Evolution:
| Model | Release | Key Advance |
|---|---|---|
| Gemini 1.0 | December 2023 | Google’s answer to GPT-4 |
| Gemini 1.5 Pro | February 2024 | 1 million token context |
| Gemini 2 | December 2024 | Advanced reasoning |
| Gemini 3 Pro | November 2025 | Most intelligent yet |
What makes Gemini unique:
- Massive context windows (1M+ tokens—entire books)
- Natively multimodal (text, image, audio, video)
- Deep Google ecosystem integration
- Deep Research Agent for autonomous research
Meta and Open Source AI
Meta made a controversial bet: give AI away for free.
When LLaMA 1 leaked in February 2023, it sparked an open-source movement. Suddenly, anyone could experiment with frontier-level models.
The LLaMA Evolution:
| Model | Release | Status |
|---|---|---|
| LLaMA 1 | February 2023 | Leaked, started it all |
| LLaMA 2 | July 2023 | First official open release |
| LLaMA 3 | April 2024 | 8B, 70B, 405B parameters |
| LLaMA 4 | April 2025 | Scout/Maverick, MoE |
Why this matters:
- Democratized LLM access
- Enabled privacy (run locally, no API)
- Spawned thousands of fine-tuned variants
- Powers Ollama, LM Studio, and the local AI movement
The Chinese AI Giants
AI isn’t just a Western phenomenon:
- DeepSeek: V3 model rivals GPT-4 at a fraction of the cost
- Alibaba (Qwen): 2.5 series, excellent multilingual capabilities
- Baidu (ERNIE): Integrated with China’s largest search engine
- Moonshot AI (Kimi): Ultra-long context pioneer (200K+ tokens)
These companies serve billions of users and represent a parallel evolution of AI technology.
The Patterns of Progress
Looking back at 75 years of AI history, certain patterns emerge.
Scaling Laws: The Secret Formula
In 2020, OpenAI researchers discovered something remarkable: model performance improves predictably with more compute.
Scaling Laws: The Secret Formula
More compute = predictably better performance
1B
Small
10B
Medium
100B
Large
1T
Very Large
3T
Frontier
📈 The Insight: OpenAI discovered in 2020 that model performance improves predictably with more compute, data, and parameters. This made AI progress plannable—just keep scaling.
Sources: OpenAI Scaling Laws Paper • Chinchilla Paper (DeepMind)
The formula: Performance scales as a power law with three factors:
- Number of parameters
- Amount of training data
- Compute (training time)
Why this matters: It made AI progress plannable. If you want a 10% improvement, here’s how much compute you need. This is why companies are investing billions in training infrastructure—they can calculate the return.
The Bitter Lesson
In 2019, AI researcher Rich Sutton published “The Bitter Lesson,” summarizing decades of AI history:
“The biggest lesson from 70 years of AI research is that general methods that leverage computation are ultimately the most effective, and by a large margin.”
Translation: Simple algorithms + massive compute beats clever engineering.
Historical examples:
- Chess: Brute-force search (Deep Blue) beat hand-crafted evaluation functions
- Vision: Learning from data beat hand-designed feature extractors
- Language: Transformers + scale beat linguistic rules and knowledge graphs
The lesson is “bitter” because it means human intuition and expertise often doesn’t help—just throw more compute at the problem.
Emergent Capabilities
Perhaps the most fascinating pattern: abilities that appear suddenly at scale.
GPT-2 couldn’t do arithmetic. GPT-3 suddenly could. What changed? More parameters, more data—same architecture.
Other emergent capabilities:
- Code generation (without code-specific training)
- Chain-of-thought reasoning
- Multi-step problem solving
- Cross-lingual transfer
Why does this happen? Honestly, researchers aren’t sure. It’s one of the mysteries of deep learning. Models seem to undergo “phase transitions”—like water suddenly freezing at 0°C.
🎯 Key Insight: Emergent capabilities mean we can’t fully predict what the next generation of models will be able to do. This is both exciting and concerning.
What’s Next: The Near Future of AI
75 Years of AI Milestones
From Turing's question to today's multimodal agents
Alan Turing asks "Can machines think?"
AI is officially born as a field
First chatbot simulates a therapist
IBM computer defeats world chess champion
Deep learning revolution begins
AI masters the game of Go
"Attention Is All You Need" published
175 billion parameters, few-shot learning
100M users in 2 months
Vision + text, passes bar exam
o1 introduces chain-of-thought
Agentic AI goes mainstream
Sources: Stanford AI Index • MIT Technology Review • OpenAI Blog
The Trajectory We’re On
Based on current trends, here’s what’s likely in the next 2-3 years:
Multimodal as default: Every major model will natively understand text, images, audio, and video. The question won’t be “Can it see images?” but “How well?”
Longer context: We’ve gone from 4K to 128K to 1M tokens. Models that can process entire codebases, book series, or years of documents will become standard.
Agent capabilities: AI that doesn’t just chat, but acts. Browse the web. Write and execute code. Control your computer. Book flights. The progression from assistant to agent is accelerating. For a deep dive, see the AI Agents guide.
Specialized models: Fine-tuned versions for law, medicine, coding, science. General capability plus deep expertise.
Edge deployment: Powerful models running on phones and laptops. Privacy through local processing.
The Big Questions
Will scaling continue to work?
Current evidence: yes. But we’ll eventually hit limits—data scarcity, energy costs, diminishing returns. When? Unknown.
When will AGI arrive?
Predictions range from 2027 (OpenAI’s optimistic estimate) to “never” (skeptics). The honest answer: we don’t know, and anyone claiming certainty is overconfident.
What about consciousness?
Most researchers say no—these are very sophisticated pattern matchers, not conscious beings. But the question is now being taken seriously, and the philosophical implications are profound.
How will society adapt?
Jobs, education, creativity, relationships, governance—all will be affected. We’re in the early stages of a transformation comparable to the industrial revolution or the internet.
The Remaining Challenges
Despite remarkable progress, fundamental problems remain:
- Hallucinations: Models still confidently generate false information
- Reasoning limits: Complex math and logic remain challenging
- Real-time learning: Models can’t learn from conversations (they’re static)
- Energy costs: Training frontier models requires enormous power
- Alignment: Ensuring AI does what we actually want, not what we say we want
Witnessing the Revolution
Looking back at 75 years of AI history, the pattern is clear: steady accumulation, punctuated by breakthrough moments.
The three eras:
- Rules (1950s-1980s): We tried to encode human knowledge. It didn’t scale.
- Learning (1990s-2016): We taught machines to learn from data. It worked—but slowly.
- Transformers (2017-present): Attention + scale = emergent intelligence.
The critical moments:
- 1956: AI is born at Dartmouth
- 2012: AlexNet proves deep learning
- 2017: “Attention Is All You Need”
- 2022: ChatGPT goes mainstream
- 2025: Agentic AI arrives
We’re living through a technological revolution comparable to the printing press, the industrial revolution, or the internet. The systems we build today will shape the next century.
Understanding this history—the failures, the winters, the breakthroughs—helps us appreciate both the power and limitations of what we’ve created. It’s not magic. It’s pattern matching at unprecedented scale to create seemingly intelligent behavior.
And we’re just getting started.
Key Takeaways
- AI evolved through three eras: Rules → Learning → Transformers
- The Transformer (2017) was the key breakthrough enabling modern LLMs
- GPT grew 25,000× from 117M to 3+ trillion parameters in 6 years
- Multiple players now compete at the frontier: OpenAI, Anthropic, Google, Meta
- Scaling laws made progress predictable—more compute = better performance
- Emergent capabilities mean we can’t fully predict what larger models can do
- The pace is accelerating, not slowing
What’s Next in This Series
Ready to dive deeper? Here’s the path ahead:
- ✅ Article 1: What Are Large Language Models?
- ✅ You are here: The Evolution of AI
- 📖 Next: How LLMs Are Trained – From Data to Intelligence
Last updated: December 2025
Related Articles: