The Architecture of Intelligence
Large Language Models (LLMs) like GPT-4, Claude, and Gemini are often anthropomorphized, but their underlying mechanisms are grounded in statistical probability, not sentient thought.
An LLM is fundamentally a prediction engine.
Trained on petabytes of text data, these models learn the statistical relationships between words (tokens). When you send a prompt, the model is not “thinking” in the human sense; it is calculating the most probable next token based on the patterns it learned during training. Understanding this process—from pre-training to reinforcement learning—demystifies why models behave the way they do (and why they sometimes fail).
This guide deconstructs the training pipeline: process. In this article, I’m going to take you behind the curtain and show you exactly how Large Language Models go from raw internet data to the intelligent assistants we use every day.
By the end, you’ll understand:
- The three-stage training pipeline (pre-training, fine-tuning, RLHF)
- How neural networks actually learn (without the math)
- Why training GPT-4 cost over $100 million
- What training data LLMs consume and how it shapes their behavior
- The human labor hidden behind every AI response
- Why LLMs sometimes “hallucinate” and make things up
Let’s dive in.
What Are Neural Networks, Really?
Before we can understand how LLMs are trained, we need to understand what they actually are. At their core, LLMs are massive neural networks—computing systems loosely inspired by the human brain.
The Biological Inspiration (But Don’t Take It Too Literally)
The name “neural network” comes from biology, but honestly, it’s a bit misleading. Real neurons are incredibly complex biological cells with chemical signals, ion channels, and intricate behaviors we barely understand. Artificial neurons are much simpler: they just do math.
Here’s a more accurate way to think about it:
A neural network is like a massive system of connected dials. Each connection has a “weight” (a number that determines influence). Information flows through billions of these connections, with each layer transforming the data until it produces an output.
If that sounds vague, here’s a concrete analogy I find helpful: think of a neural network as a very complex spreadsheet with billions of formulas. Each cell takes inputs from other cells, does some math, and passes its result to the next layer.
How Neural Networks Learn: The Core Insight
Here’s the key insight that makes neural network training work: learning is just adjusting the weights to reduce errors.
The process, simplified:
- Show the network an example - “The cat sat on the ___”
- Get its prediction - Maybe it says “table” (wrong)
- Calculate how wrong it was - This is called the “loss”
- Adjust the weights slightly to reduce that error
- Repeat billions of times across trillions of examples
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart LR
A["Example: 'The cat sat on the ___'"] --> B["Neural Network"]
B --> C["Prediction: 'table'"]
C --> D["Calculate Error"]
D --> E["Adjust Weights"]
E --> BThis process is called gradient descent, and it’s the fundamental algorithm behind all deep learning. The “gradient” tells the network which direction to adjust each weight to reduce the error, and “descent” means we’re trying to find the lowest error possible.
Parameters: What the Model “Knows”
When people say “GPT-4 has 1.76 trillion parameters,” they’re talking about the weights learned during training. These parameters ARE the model—everything it “knows” is encoded in these numbers.
Here’s what’s fascinating: parameters don’t store facts directly. They store patterns and relationships. The model doesn’t have a database entry saying “Paris is the capital of France.” Instead, it has patterns that make it incredibly likely to complete “The capital of France is ___” with “Paris.” For a deeper exploration, see the Tokens, Context Windows & Parameters guide.
| LLM | Parameters | Analogy |
|---|---|---|
| GPT-2 (2019) | 1.5 billion | Small sedan engine |
| GPT-3 (2020) | 175 billion | Jet engine |
| GPT-4 (2023) | ~1.76 trillion | Rocket engine |
| LLaMA 3 (2024) | 405 billion | Commercial airliner |
The Transformer Architecture: Why It Changed Everything
You can’t understand LLM training without understanding Transformers—the architecture that powers ChatGPT, Claude, Gemini, and every major LLM.
The Problem with Sequential Processing
Before 2017, language models used architectures called RNNs (Recurrent Neural Networks) and LSTMs. These processed text word by word, sequentially—like reading a sentence one word at a time while trying to remember everything that came before.
This approach had major problems:
- Slow: You can’t parallelize sequential processing
- Forgetting: Information from early words gets diluted over distance
- Long-range dependencies: Connecting “cat” to “ran” in “The cat that the dog chased ran away” was difficult
The 2017 Breakthrough: “Attention Is All You Need”
In June 2017, Google researchers published a paper that changed everything. The title was simple but profound: “Attention Is All You Need.”
The core innovation was the self-attention mechanism. Instead of processing words sequentially, attention lets every word “look at” every other word directly—all at once, in parallel.
Here’s how I think about it:
Imagine highlighting a paragraph while answering a question. You don’t read every word equally—you focus on what’s relevant. Attention does the same thing: it lets the model focus on important words regardless of their position in the sequence.
Example: “The bank was steep, and the canoe could easily tip over.”
To understand that “bank” means riverbank (not financial institution), the model needs to attend to “steep,” “canoe,” and “tip over.” Attention captures these contextual connections directly.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart TB
A["Input Text"] --> B["Token Embeddings"]
B --> C["+ Position Encodings"]
C --> D["Self-Attention Layer"]
D --> E["Feed-Forward Network"]
E --> F["Repeat N Times"]
F --> G["Output Probabilities"]Why Transformers Won
| Feature | RNN/LSTM | Transformer |
|---|---|---|
| Processing | Sequential (slow) | Parallel (fast) |
| Long-range context | Degrades over distance | Excellent at any distance |
| Training speed | Hours for short sequences | Scales with compute |
| Scalability | Limited by architecture | Scales to trillions of parameters |
The result? Transformers can be trained on massive compute clusters efficiently. More GPUs = faster training. This, combined with scaling laws, led to the explosion in model size we’ve seen over the past five years.
GPT, Claude, Gemini, LLaMA—all built on the Transformer architecture. It’s one of the most influential papers in AI history.
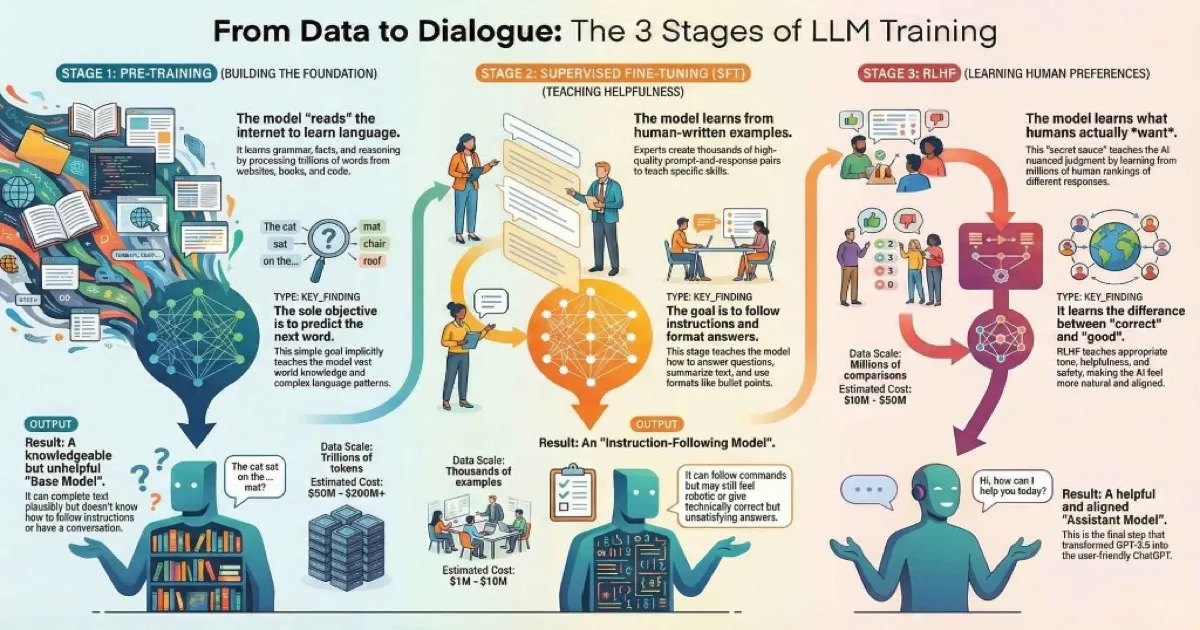
The Three Stages of LLM Training
Now we’re ready for the main event. Training an LLM isn’t a single process—it’s a carefully orchestrated pipeline with three distinct stages, each building critical capabilities.
The Three Stages of LLM Training
Click each stage to explore details
Pre-training
The model "reads" the internet, learning grammar, facts, reasoning, and how language works.
💡 Analogy: Like a student spending 20 years reading every book in every library in the world.
Duration
Months
Cost
$50M-200M+
Data
Trillions of tokens
Goal
Learn language patterns
Sources: InstructGPT Paper • Anthropic RLHF • Stanford AI Index
Think of it like raising a child to become a helpful expert:
- Pre-training: The child reads every book ever written, learning how language works
- Fine-tuning (SFT): The child takes a customer service course, learning to be helpful
- RLHF: The child gets feedback from thousands of people about what actually makes them happy
Let’s dive into each stage.
Stage 1: Pre-training — Reading the Internet
Pre-training is the foundational phase where the model learns language patterns. It’s also the most expensive and time-consuming part of training.
The Training Objective: Predict the Next Token
Here’s what blew my mind when I first learned it: the entire objective of pre-training is next-word prediction.
That’s it. Given some text, predict what comes next.
- “The capital of France is ___” → “Paris”
- “def fibonacci(n):” → “return” (or similar code)
- “E = mc” → “²”
The model sees trillions of these examples. By learning to predict well, it implicitly learns grammar, facts, reasoning, writing styles, and much more.
| Input | Target | What the Model Learns |
|---|---|---|
| ”The cat sat on the" | "mat” | Common phrases, grammar |
| ”E = mc" | "²” | Scientific notation |
| ”def fibonacci(n):" | "return” or similar | Code syntax |
| ”In 1969, humans first" | "landed” | Historical facts |
| ”The patient presents with” | medical terminology | Domain-specific language |
What Training Data Do LLMs Consume?
LLMs are trained on massive text datasets scraped from across the internet and beyond:
- Common Crawl: Petabytes of web pages scraped from billions of URLs
- Books: Thousands of digitized books (fiction, non-fiction, textbooks)
- Wikipedia: Encyclopedic knowledge in many languages
- Academic Papers: ArXiv, PubMed, and other repositories
- Code: GitHub repositories, Stack Overflow
- Conversations: Reddit, forums, chat logs
- Specialized: Legal documents, patents, medical literature
Training Data Composition
Estimated mix for modern LLMs like GPT-4
📊 Key Insight: Web data dominates, but data quality matters more than quantity. Modern LLMs use sophisticated filtering to remove noise, duplicates, and harmful content.
~15T
Tokens processed
~45TB
Raw data size
Sources: Common Crawl • LLaMA Paper • Epoch AI
Data Quality: The Hidden Key
Here’s something that took me a while to understand: more data isn’t always better—quality matters enormously.
Modern LLM training involves sophisticated data curation:
- Deduplication: Remove repeated content (prevents memorization)
- Filtering: Remove toxic, illegal, or low-quality content
- Language detection: Keep target languages
- Quality scoring: Rate text quality using classifiers
- Domain balancing: Mix different types of content appropriately
As one researcher put it: “Data curation is 50% of the work.”
What Pre-Training Teaches
After pre-training, the model understands:
- ✅ Language structure (grammar, syntax across languages)
- ✅ World knowledge (facts, history, science)
- ✅ Reasoning patterns (if-then, cause-effect)
- ✅ Multiple writing styles (formal, casual, technical, creative)
- ✅ Code syntax for many programming languages
- ✅ Multilingual capabilities
What Pre-Training Does NOT Teach
But here’s what pre-training can’t do:
- ❌ How to be helpful (it just continues text)
- ❌ How to refuse harmful requests
- ❌ How to format responses nicely
- ❌ How to admit uncertainty
- ❌ Specific user preferences
After pre-training, you have what’s called a base model or foundation model. It can complete any text in plausible ways, but it’s not an assistant yet. For more on how these models are customized further, see the Fine-Tuning and Customizing LLMs guide.
Example: If you ask a base model “What is the capital of France?”, it might respond with “This is a common geography question…” instead of just saying “Paris.”
The base model has knowledge, but it doesn’t know how to have a conversation.
Stage 2: Supervised Fine-Tuning — Learning to Be Helpful
Fine-tuning transforms that raw knowledge engine into something that actually follows instructions and helps users.
The Problem with Base Models
Think of a pre-trained model like a brilliant scholar who has read everything ever written but has terrible social skills:
- They’ll answer a question by rambling for twenty minutes
- They don’t know when to stop talking
- They might give true information buried in irrelevant prose
- They don’t understand the difference between a question and a statement
Supervised Fine-Tuning (SFT) fixes this.
How SFT Works
Instead of predicting random internet text, the model now trains on carefully curated conversation examples:
| User Prompt | Ideal Response |
|---|---|
| ”Write a haiku about coding” | Three-line poem about programming |
| ”Explain recursion simply” | Clear analogy + simple example |
| ”Is this Python code correct? [code]“ | Identifies bug, explains fix |
| ”Summarize this article: [text]“ | Concise 3-paragraph summary |
| ”Help me decline a meeting professionally” | Polite, professional email draft |
Human experts write thousands of these examples. The process is expensive—it requires domain experts (doctors, lawyers, coders) who can write high-quality responses.
What SFT Teaches the Model
After fine-tuning, the model learns:
- ✅ Instruction following (“Write a poem about…”)
- ✅ Response formatting (bullet points, numbered lists, code blocks)
- ✅ Appropriate tone and length
- ✅ Question answering vs text completion
- ✅ Task-specific skills (summarization, translation, coding)
- ✅ Basic safety behaviors
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart LR
A["Base Model"] --> B["SFT Training"]
C["Human-Written Examples"] --> B
B --> D["Instruction-Following Model"]The Limitations of SFT
But SFT has limits:
- It can only teach what humans explicitly write
- It doesn’t capture subtle preferences (“I prefer this response over that one”)
- The model might still give technically correct but unsatisfying answers
- You can’t write examples for every possible situation
This is where the magic really happens.
Stage 3: RLHF — Learning What Humans Actually Want
RLHF (Reinforcement Learning from Human Feedback) is what transformed GPT-3.5 into ChatGPT. It’s the “secret sauce” that makes modern AI assistants feel so natural.
Why RLHF Is Necessary
Consider two responses to “Explain black holes to a 10-year-old”:
| Response A | Response B |
|---|---|
| ”A black hole is a region of spacetime where gravity is so strong that nothing, not even light or other electromagnetic waves, has enough energy to escape the event horizon." | "Imagine a cosmic vacuum cleaner so powerful that even light can’t escape! When a super-massive star dies, it collapses into a tiny point but keeps all its gravity. Anything that gets too close gets pulled in forever!” |
Both are technically correct. But for a 10-year-old, Response B is clearly better—more engaging, uses analogies, appropriate complexity.
SFT can’t easily capture this distinction. Both responses “follow the instruction.” But humans have preferences, and those preferences are hard to write down as rules.
RLHF captures preferences at scale.
How RLHF Works
The feedback loop that creates helpful assistants
Generate Responses
For each prompt, the model generates multiple candidate responses.
🎯 Why It Matters: RLHF is what transformed GPT-3.5 from a text completion engine into ChatGPT—the difference between "technically correct" and "actually helpful".
Sources: InstructGPT Paper • Anthropic
The Three-Step RLHF Process
Step 1: Collect Comparison Data
For each prompt, generate multiple responses. Human raters rank them:
- “A is better than B”
- Based on helpfulness, honesty, safety, clarity
Step 2: Train a Reward Model
A separate model learns to predict human rankings:
- Input: A prompt and a response
- Output: A score predicting how much humans would like it
This reward model becomes a “learned preference function.”
Step 3: Optimize the LLM Using Reinforcement Learning
- The LLM generates responses
- The reward model scores them
- The LLM adjusts to produce higher-scoring responses
- Repeat until consistently producing preferred outputs
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart TB
A["LLM Generates Responses"] --> B["Reward Model Scores Them"]
B --> C["Calculate Gradient"]
C --> D["Update LLM Weights"]
D --> AWhat RLHF Teaches the Model
- ✅ Nuanced judgment about “better” vs “correct”
- ✅ Appropriate level of detail for the audience
- ✅ When to admit uncertainty vs when to be confident
- ✅ How to refuse harmful requests gracefully
- ✅ Balancing helpfulness with safety
- ✅ Matching user’s tone and expectations
The Hidden Human Labor
Here’s something important that often gets overlooked: RLHF requires massive amounts of human judgment.
Thousands of contractors rate millions of responses. This work is often outsourced to lower-wage countries, and there are real ethical concerns:
- Raters are exposed to harmful content they must evaluate
- Pay is often low relative to the psychological difficulty
- The “AI” has very human fingerprints all over it
Every polite refusal, every well-structured explanation, every appropriate caveat—all of that traces back to human raters teaching the model what “good” looks like. For more on the ethical considerations of AI development, see the Understanding AI Safety, Ethics, and Limitations guide.
The ChatGPT Moment
ChatGPT wasn’t a new model—it was GPT-3.5 with RLHF applied.
That’s it. The same base model, but trained to actually satisfy human preferences rather than just complete text.
RLHF is the difference between “technically helpful” and “actually helpful.” It’s why ChatGPT felt magical to millions of users who had never engaged with AI before.
The Complete Training Pipeline
Let’s bring it all together:
| Stage | Goal | Data | Time | Cost |
|---|---|---|---|---|
| Pre-training | Learn language patterns | Trillions of tokens | Months | $50M-$200M+ |
| SFT | Learn to follow instructions | Thousands of examples | Days-Weeks | $1M-$10M |
| RLHF | Learn human preferences | Millions of comparisons | Weeks | $10M-$50M |
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart LR
A["Raw Text Data\n(Trillions of tokens)"] --> B["Pre-training\n(Months)"]
B --> C["Base Model"]
C --> D["SFT\n(Days)"]
E["Human Examples\n(Thousands)"] --> D
D --> F["Instruction Model"]
F --> G["RLHF\n(Weeks)"]
H["Human Preferences\n(Millions)"] --> G
G --> I["Assistant Model"]
I --> J["Deployed! 🚀"]Why Each Stage Matters
- Skip pre-training? Model has no knowledge or language understanding
- Skip SFT? Model completes text but doesn’t answer questions
- Skip RLHF? Model follows instructions but feels robotic and unsatisfying
Each stage builds critical capabilities the next stage depends on.
The Infrastructure Behind Training
Understanding the infrastructure helps explain why only a handful of organizations can train frontier models.
The GPU Arms Race
Training clusters have grown massively
$25K+
Per H100 GPU
~700W
Per GPU power
~100MW
Full cluster
⚡ Scale Context: A 100,000 GPU cluster costs over $2.5 billion in hardware alone, consumes as much power as a small city, and requires specialized data centers with advanced cooling.
Sources: NVIDIA • The Information • Reuters
Why Training Costs Millions
Training GPT-4 required an estimated:
- ~25,000 Nvidia A100 GPUs running for ~90 days
- Each A100 costs $10,000+; H100s cost $25,000-$40,000
- Electricity for running and cooling: megawatts of power
- Plus: data center space, networking, engineers, data curation
Training Cost Explosion
Costs increased 4,000× from GPT-2 to Gemini Ultra
💸 Trend: Training costs are growing faster than Moore's Law. Only a handful of organizations can afford frontier model training, creating a "compute divide" in AI development.
Sources: Lambda Labs • Epoch AI • Stanford AI Index
The Hardware Stack
| Component | Role | Scale |
|---|---|---|
| GPUs (A100, H100) | The “brains” that do the math | 10,000-100,000 per run |
| High-speed networking | GPUs must communicate constantly | InfiniBand at 400+ Gbps |
| Storage | Training data, checkpoints, logs | Petabytes |
| Cooling | Prevent overheating | Liquid cooling common |
| Power | Run it all | Megawatts (small power plant) |
Why GPUs?
Neural network training involves millions of small math operations that can happen in parallel. CPUs are designed for complex sequential tasks. GPUs are designed for simple parallel tasks.
Training is “embarrassingly parallel”—perfect for GPUs.
The Democratization Challenge
Only a handful of organizations can afford frontier model training:
- OpenAI, Anthropic, Google, Meta, xAI, a few others
Smaller players focus on fine-tuning existing models, not training from scratch. Open-source models like LLaMA democratize access but not creation.
What Training Doesn’t Give You
Understanding the limitations of training is just as important as understanding the process.
The Illusion of Understanding
LLMs learn patterns, not concepts. “Paris is the capital of France” is a pattern, not a fact the model “believes.”
There’s no internal model of truth vs falsehood. The model can’t distinguish “I know this” from “I’m guessing.” This is why hallucinations are a fundamental feature, not a bug.
Things Training Cannot Provide
| Capability | Why Training Doesn’t Provide It |
|---|---|
| Real-time knowledge | Training data has a cutoff date |
| True reasoning | Pattern matching, not logical deduction |
| Learning from conversations | No weight updates after deployment |
| Personal memory | Each conversation starts fresh |
| Physical understanding | Never experienced the world |
| Mathematical precision | Predicts digits, doesn’t calculate |
| Source verification | Doesn’t “know” where info came from |
Why LLMs Hallucinate
LLMs are trained to produce plausible text, not true text. The training objective rewards outputs that look like what a human would write, not outputs that are factually correct.
When uncertain, the model generates what sounds right rather than saying “I don’t know.” This is why you should always verify LLM outputs for anything consequential.
🎯 My Rule: Treat LLMs like a very smart colleague who sometimes confidently makes things up. Appreciate their drafts and ideas, but always double-check critical facts.
Emerging Training Techniques
The field is evolving rapidly. Here are some techniques you’ll hear about:
| Technique | What It Does | Used By |
|---|---|---|
| Constitutional AI | Model critiques itself using principles | Anthropic (Claude) |
| DPO | Direct Preference Optimization—skip reward model | Growing adoption |
| RLAIF | Use AI to generate preference rankings | Claude, others |
| Mixture of Experts (MoE) | Route inputs to specialized sub-models | GPT-4, Mixtral |
| Distillation | Train small models on outputs of large models | Phi, Orca |
| Synthetic Data | AI-generated training data | Phi models |
For a comprehensive guide to modern fine-tuning techniques, see the Fine-Tuning and Customizing LLMs guide.
Mixture of Experts: More Efficient Scaling
Instead of one giant network, MoE uses many specialized “experts.” A “router” decides which experts to use for each input, meaning only a fraction of parameters are active at any time.
GPT-4 uses this architecture—estimated 8 experts with ~220B parameters active per input, even though the total is ~1.76T.
Synthetic Data: AI Training AI
Using LLM outputs as training data for other LLMs is increasingly common. Microsoft’s Phi models are trained largely on synthetic data generated by larger models.
Risks include amplifying errors and “model collapse,” but benefits include infinite data generation and curriculum control.
What This Means for You
Understanding training helps you use LLMs more effectively:
- Know when to trust: Common patterns are reliable; rare topics may hallucinate
- Recognize limitations: Real-time info, math, and recent events are weak spots
- Appreciate the human element: Behind every helpful response is human feedback
- Use prompting wisely: Clear instructions work better because that’s how SFT data looks
- Verify important outputs: The model optimizes for plausibility, not truth
For detailed prompting techniques, see the Prompt Engineering Fundamentals guide.
Key Takeaways
Let’s wrap up with the essential points:
- Three stages: Pre-training (knowledge), SFT (helpfulness), RLHF (alignment)
- Neural networks learn by adjusting billions of parameters to predict the next word
- Transformers enabled scaling through parallel processing and attention
- Training data composition profoundly shapes model capabilities and biases
- Training costs tens to hundreds of millions of dollars
- RLHF is what makes models feel “intelligent” and “helpful”
- Despite sophistication, LLMs are pattern matchers—not reasoners or truth-seekers
Now you understand the journey from raw internet data to the intelligent assistants we chat with every day. The next time you use ChatGPT or Claude, you’ll know: behind every response is trillions of tokens, thousands of human examples, millions of comparisons, and tens of millions of dollars in infrastructure.
Pretty remarkable, right?
What’s Next?
Ready to go deeper? Here’s the suggested path:
- ✅ You are here: How LLMs Are Trained
- 📖 Previous: The Evolution of AI
- 📖 Start: What Are Large Language Models?
Related Articles:
- LLM Benchmark Tracker - Compare the latest benchmark scores across all major models
- What Are Large Language Models? A Beginner’s Guide
- The Evolution of AI - From Rule-Based Systems to GPT-5