Demystifying the Technology
Large Language Models (LLMs) represent a paradigm shift in computing. Unlike traditional software, which follows explicit instructions code by humans, LLMs learn patterns from vast datasets to generate human-like text, code, and analysis key. For a deeper dive into how these models are trained, see the How LLMs Are Trained guide.
We have moved from explicit programming to probabilistic generation.
While models like ChatGPT, Claude, and Gemini may seem to “understand” questions, they are actually performing complex statistical predictions to determine the most likely next word in a sequence. Understanding this distinction—between true comprehension and statistical mimicry—is crucial for using these tools effectively.
This guide serves as a technical introduction to the mechanisms behind Large Language Models:
100M+
ChatGPT users in 2 months
175B
GPT-3 parameters
$100M+
GPT-4 training cost
~1.76T
GPT-4 parameters (est.)
Sources: Statista • OpenAI Papers • Forbes • Wikipedia
First, Let’s Clear Up the Confusion: AI vs ML vs LLMs
One thing that confused me early on was all the overlapping terms. AI, Machine Learning, Deep Learning, LLMs—people throw these around interchangeably, but they’re actually different things. Think of them as nested boxes, each one fitting inside the larger one.
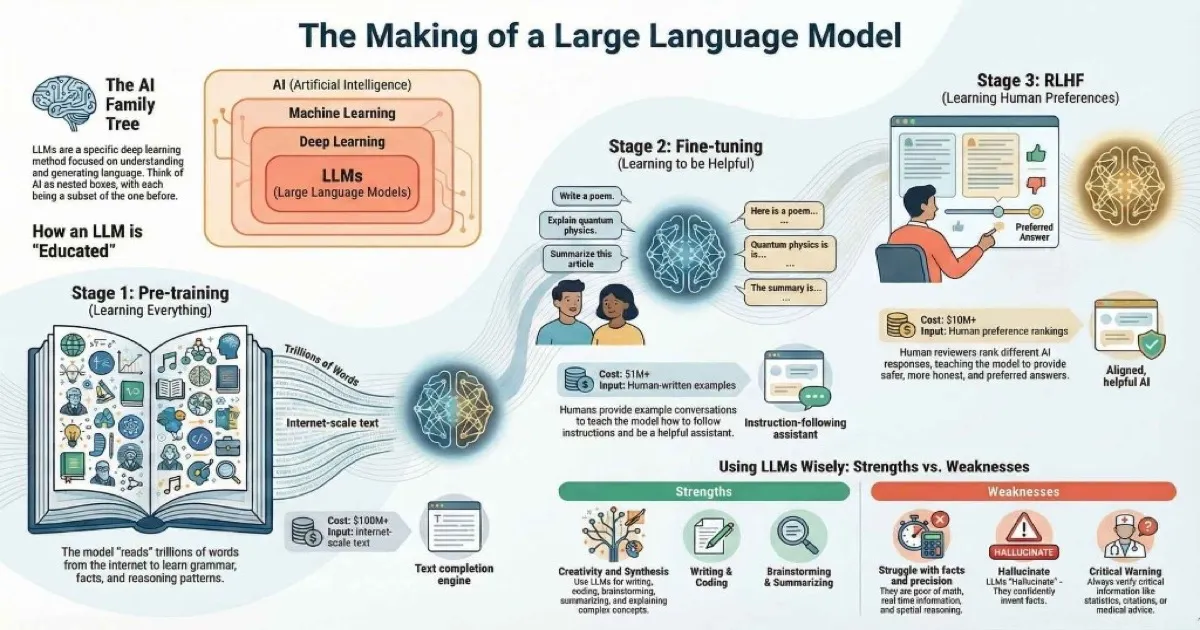
The AI Family Tree
Here’s how I like to visualize it:
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart TB
AI["Artificial Intelligence"]
ML["Machine Learning"]
DL["Deep Learning"]
LLM["Large Language Models"]
AI --> ML
ML --> DL
DL --> LLMLet me break each one down:
Artificial Intelligence (AI) is the broadest term. It just means machines doing things that normally require human smarts—playing chess, recognizing faces, understanding speech. AI has been around since the 1950s, long before anyone dreamed of ChatGPT.
Machine Learning (ML) is a subset of AI. Instead of programming a computer with explicit rules (“if the email contains ‘Nigerian prince’, mark as spam”), you feed it thousands of examples and let it figure out the patterns. The more data, the smarter it gets.
Deep Learning takes ML further by using neural networks—computing systems loosely inspired by the human brain. These networks have many “layers” that process information, which is why we call it “deep.” This is what powers things like voice assistants and photo recognition.
Large Language Models (LLMs) are a specific type of deep learning focused on language. They’re trained on massive amounts of text—books, websites, code, conversations—and learn to understand and generate human language. ChatGPT, Claude, and Gemini are all LLMs. For a comparison of these AI assistants, see the AI Assistant Comparison guide.
Here’s a simple analogy that helped me:
AI = All vehicles
Machine Learning = Self-driving vehicles
Deep Learning = Tesla’s autopilot system
LLMs = Tesla’s voice command understanding
The impact of LLMs has been nothing short of explosive. Just look at how quickly ChatGPT was adopted compared to other groundbreaking products:
Fastest to 1 Million Users
ChatGPT broke all records for product adoption
📈 Record Breaking: ChatGPT reached 100 million monthly active users in just 2 months, making it the fastest-growing consumer application in history.
Sources: Statista • Britannica • Reuters
The Surprisingly Simple Secret Behind LLMs
Here’s something that blew my mind when I first learned it: at their core, LLMs are incredibly sophisticated autocomplete systems.
That’s it. That’s the secret.
When you type a message to ChatGPT, it’s essentially predicting “what’s the most likely next word?” over and over again. You type “The cat sat on the…” and it predicts “mat” (or “couch” or “keyboard”—every cat owner knows that one).
But here’s where it gets interesting. When you scale this simple concept up to billions of calculations running on data from essentially the entire internet, something remarkable happens. The model doesn’t just predict individual words—it starts generating coherent paragraphs, telling jokes, writing code, and explaining quantum physics in ways a five-year-old could understand.
How I Think About It
Imagine you’ve read every book ever written, every Wikipedia article, every Reddit thread, and every code repository on GitHub. You wouldn’t memorize all that text word-for-word, but you’d develop an intuitive sense for how language works—how sentences flow, how arguments build, how different topics connect.
That’s essentially what an LLM does during training. It develops statistical patterns about language that are so rich and nuanced that the outputs feel intelligent.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart LR
A["Your Prompt"] --> B["Tokenization"]
B --> C["Neural Network"]
C --> D["Probability"]
D --> E["Word Selection"]
E --> F["Response"]
E -.->|Repeat| DHere’s the step-by-step process:
- You type a prompt - “Explain photosynthesis like I’m five”
- Tokenization - Your words get converted into numbers (tokens)
- Neural network processing - These numbers flow through billions of calculations
- Probability distribution - The model calculates the probability of every possible next word
- Word selection - It picks a word (with some controlled randomness for creativity)
- Repeat - This process repeats until the response is complete
The whole thing happens in milliseconds. Pretty wild, right?
The Three Stages of LLM Training
I find it helpful to understand how these models are actually trained. It’s like understanding how a chef learned to cook—it gives you insight into their strengths and limitations.
Think of training an LLM like raising a child who will become a helpful assistant. There are three distinct phases, each building on the last.
Stage 1: Pre-training (Learning to Read Everything)
The Goal: Teach the model how language works.
This is the most expensive and time-consuming phase. The model “reads” essentially the entire internet—billions of web pages, books, articles, Wikipedia, code repositories, scientific papers, social media posts, and more.
How it works:
- The model sees a sentence with a missing word: “The cat sat on the ___”
- It predicts the next word (maybe “mat” or “couch”)
- If it’s wrong, the model adjusts its internal connections slightly
- Repeat this trillions of times across all that text
What it learns:
- ✅ Grammar and syntax (how sentences are structured)
- ✅ Facts and knowledge (who was the first president, what is photosynthesis)
- ✅ Reasoning patterns (if X then Y, cause and effect)
- ✅ Writing styles (formal vs casual, technical vs creative)
- ✅ Multiple languages and their relationships
- ✅ Code syntax for dozens of programming languages
Real-world analogy: Imagine a student who spends 20 years reading every book in the world’s largest library. They don’t memorize word-for-word, but they develop an incredible intuition for how language works, what topics relate to each other, and how different writing styles feel.
Duration: Weeks to months using thousands of GPUs
Cost: $4.6 million for GPT-3, $100+ million for GPT-4
💡 Key insight: After pre-training, the model can complete text, but it’s not particularly helpful. If you ask “What’s the capital of France?”, it might continue with “…is a common trivia question” instead of just answering “Paris.”
Stage 2: Fine-tuning (Learning to Be Helpful)
The Goal: Transform a text-completion engine into a helpful assistant.
Raw pre-trained models are like brilliant scholars with no social skills. They know a lot but don’t know how to have a conversation or follow instructions. Fine-tuning fixes this.
How it works:
- Humans create thousands of example conversations:
- User: “Explain quantum computing in simple terms”
- Assistant: “Imagine you have a coin that’s spinning in the air…”
- The model learns to match this helpful, conversational style
- This is called Supervised Fine-Tuning (SFT)
What it learns:
- ✅ How to follow instructions (“Write a poem about…”)
- ✅ How to format responses appropriately (bullet points, code blocks, etc.)
- ✅ How to be polite and professional
- ✅ How to ask clarifying questions when needed
- ✅ How to decline harmful requests gracefully
Training data examples:
| User Input | Desired Response |
|---|---|
| ”Summarize this article” | A concise 3-paragraph summary |
| ”Write Python code to sort a list” | Working code with comments |
| ”Help me with my resume” | Structured feedback and suggestions |
| ”How do I hack into…” | Polite refusal explaining why |
Real-world analogy: After years of reading, our scholar now takes a customer service training course. They learn how to greet people, how to structure helpful answers, how to stay calm with difficult questions, and when to escalate to a human.
Duration: Days to weeks
Cost: Much less than pre-training (smaller dataset, fewer iterations)
Stage 3: RLHF (Learning Human Preferences)
The Goal: Make the model not just helpful, but preferably helpful—aligned with what humans actually want.
This is the “magic sauce” that makes modern LLMs feel so natural to talk to. RLHF stands for Reinforcement Learning from Human Feedback.
How it works:
- The model generates multiple responses to the same prompt
- Human reviewers rank them: “Response A is better than Response B”
- A “reward model” learns to predict human preferences
- The LLM is trained to maximize this reward signal
Example in action:
Prompt: “Explain black holes to a 10-year-old”
| Response A | Response B |
|---|---|
| ”A black hole is a region of spacetime where gravity is so strong that nothing, not even light or other electromagnetic waves, has enough energy to escape the event horizon." | "Imagine a cosmic vacuum cleaner so powerful that even light can’t escape! When a super-massive star dies, it collapses into a tiny point, but still has all its gravity. Anything that gets too close gets pulled in forever—even sunlight!” |
Humans would rank Response B higher for a child audience. The model learns this preference.
What it learns:
- ✅ Honest answers are preferred over confident-but-wrong ones
- ✅ Helpful responses are preferred over evasive ones
- ✅ Safe responses are preferred over harmful ones
- ✅ Nuanced responses are preferred over oversimplified ones
- ✅ Acknowledging uncertainty is preferred over making things up
Real-world analogy: Our customer service representative now gets detailed feedback from thousands of customers. “Your answer was technically correct but too complicated.” “I loved how you explained that!” “You should have asked what I already knew first.” Over time, they develop excellent judgment about what makes people happy.
Duration: Weeks (ongoing refinement)
Key companies doing this well: Anthropic (Claude), OpenAI (ChatGPT), Google (Gemini)
The Full Pipeline Visualized
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart LR
A["Pre-training"] --> B["Fine-tuning"]
B --> C["RLHF"]
C --> D["Ready!"]| Stage | Input | Output | Time | Cost |
|---|---|---|---|---|
| Pre-training | Internet-scale text | Text completion engine | Months | $100M+ |
| Fine-tuning | Human-written examples | Instruction-following assistant | Days | $1M+ |
| RLHF | Human preference rankings | Aligned, helpful AI | Weeks | $10M+ |
🎯 Why this matters for you: Understanding these stages helps you work better with LLMs. Pre-training explains why they know so much. Fine-tuning explains why they try to be helpful. RLHF explains why they sometimes refuse requests or express uncertainty.
The Numbers Behind the Magic: Tokens, Context Windows, and Parameters
I used to glaze over when people threw around terms like “128K context window” or “70 billion parameters.” Let me translate these into something that actually makes sense.
Tokens: The Building Blocks
LLMs don’t read words—they read tokens. A token is usually a word or part of a word.
Here are some real examples:
| Text | Tokens | Count |
|---|---|---|
| ”Hello” | [Hello] | 1 token |
| ”Unbelievable” | [Un] [believable] | 2 tokens |
| ”ChatGPT” | [Chat] [GPT] | 2 tokens |
| ”I love pizza” | [I] [love] [pizza] | 3 tokens |
Why this matters: LLMs have token limits and pricing is usually per token. A rough rule: 1 token ≈ 4 characters or about ¾ of a word.
Context Window: The Model’s Memory
This is how much text the model can “see” at once. Think of it as working memory—how much of the conversation (or document) the model can consider when generating a response.
Here’s how current models compare (as of December 2025):
| Model | Context Window | What That Means |
|---|---|---|
| GPT-4 (2023) | 128K tokens | ~100,000 words (a long novel) |
| GPT-5.2 (2025) | 256K tokens | ~200,000 words (two novels) |
| Claude Opus 4.5 | 200K tokens | ~150,000 words |
| Gemini 3 Pro | 1M+ tokens | ~750,000 words (entire book series) |
When I first started using AI tools, I didn’t realize why conversations would sometimes “forget” earlier context. Now I understand—older messages get pushed out of the context window.
Parameters: The Model’s “Brain Size”
Parameters are the adjustable values the model learned during training. Think of them as connection strengths between neurons—the relationships the model has discovered about language.
More parameters generally means more capable, but also slower and more expensive:
| Model | Parameters | Analogy |
|---|---|---|
| GPT-2 (2019) | 1.5 billion | Small car engine |
| GPT-3 (2020) | 175 billion | Jet engine |
| GPT-4 (2023) | ~1.8 trillion | Rocket engine |
| GPT-5.2 (2025) | ~3+ trillion | Space shuttle |
The jump from GPT-3 to GPT-4 to GPT-5 isn’t just about more parameters—it’s also about better training techniques and data quality. But size generally correlates with capability.
The Exponential Growth of LLMs
Model parameters have grown 15,000× in 5 years
🚀 Key Insight: GPT-4 has approximately 15,000× more parameters than GPT-1. This exponential scaling is a key driver of emergent capabilities.
Sources: OpenAI GPT-3 Paper • Wikipedia - GPT-4 • NVIDIA Blog
And with this growth comes staggering costs. Training these models requires massive computational resources:
The Cost of Training LLMs
Training costs have exploded 4,000× since 2020
$191M
Gemini Ultra (highest confirmed)
$100M+
GPT-4 training cost
Sources: Lambda Labs • Forbes • Stanford AI Index
Why LLMs Feel So Smart (And Where They Fall Short)
This is where things get philosophically interesting. When you chat with Claude or ChatGPT, it feels like you’re talking to something intelligent. But are these models actually “thinking”?
The honest answer is: we’re not entirely sure. What we do know is that their behavior is remarkably sophisticated—and understanding both their strengths and limitations will make you a much more effective user.
The Emergence of Intelligence
Here’s what fascinates researchers and users alike: LLMs exhibit behaviors they were never explicitly taught.
No one programmed GPT-4 to:
- Write poetry in the style of Shakespeare
- Debug complex code across multiple programming languages
- Explain quantum physics using cooking analogies
- Roleplay as a medieval knight with consistent character
- Translate idioms naturally between languages
These abilities emerged from scale—the combination of massive training data and billions of parameters somehow produces capabilities that seem almost magical.
%%{init: {'theme': 'base', 'themeVariables': { 'primaryColor': '#4f46e5', 'primaryTextColor': '#ffffff', 'primaryBorderColor': '#3730a3', 'lineColor': '#6366f1', 'fontSize': '16px' }}}%%
flowchart TB
A["Scale"] --> B["Emergent Abilities"]
B --> C["Creative Writing"]
B --> D["Code Generation"]
B --> E["Math Reasoning"]
B --> F["Translation"]
B --> G["Role-Playing"]Why does this happen? When you train on enough human-generated text, you’re not just learning words—you’re learning the patterns of human thought itself. How we reason. How we explain. How we create. The model develops what researchers call “world models”—internal representations of how things work.
It’s like how a child who reads enough stories starts creating their own—but compressed into a training process measured in weeks rather than years.
What LLMs Are Great At
After months of daily use across different tools, here’s where I’ve found LLMs genuinely shine:
| Capability | Examples | Why They Excel |
|---|---|---|
| Writing & Editing | Emails, reports, blog posts, tone adjustments | Trained on billions of text examples |
| Explaining Concepts | ”Explain X like I’m 5”, analogies, breakdowns | Pattern-matched countless explanations |
| Coding Assistance | Writing, debugging, refactoring, explaining code | Trained on GitHub’s entire codebase |
| Brainstorming | Ideas, alternatives, edge cases, perspectives | Can quickly generate many variations |
| Translation | Between languages, also between technical/simple | Deep understanding of language structure |
| Summarization | Long documents → key points | Excellent at identifying what matters |
| Research Synthesis | Combining info from multiple sources | Can hold large context and synthesize |
| Creative Writing | Stories, poems, scripts, dialogue | Learned from master storytellers |
For practical applications, see the AI for Everyday Productivity guide. For advanced AI capabilities, explore our AI Agents guide.
Pro tips for getting the best results:
-
Be specific - “Write a professional email” is okay; “Write a professional email to a client explaining a 2-week delay due to supply chain issues, apologetic but confident in tone” is much better
-
Provide context - Tell the model who you are, who the audience is, what you’ve tried
-
Iterate - First response rarely perfect; refine with follow-ups like “make it shorter” or “more casual tone”
-
Use roles - “You are an expert copywriter with 20 years of experience” can dramatically improve output quality
Where LLMs Struggle
Understanding limitations is just as important as knowing strengths. Here’s where LLMs consistently fall short:
| Limitation | Example | Why It Happens |
|---|---|---|
| Math & Calculations | ”What’s 17 × 24?” often wrong | They predict digits, don’t compute |
| Real-time Information | ”What happened today?” | Training data has a cutoff date |
| Counting | ”How many R’s in strawberry?” | Tokenization makes character-level tasks hard |
| Spatial Reasoning | ”If I face north and turn right…” | No physical understanding |
| Consistent Memory | Forgetting earlier conversation context | Limited context window, no persistent memory |
| Truly Novel Ideas | Breakthrough scientific discoveries | Can only recombine existing patterns |
| Personal Experiences | ”What does chocolate taste like?” | No senses, no embodiment |
The “Stochastic Parrot” Debate
Some researchers argue LLMs are just “stochastic parrots”—systems that predict statistically likely next words without any real understanding. Others believe something deeper is happening—that these systems have developed genuine (if limited) reasoning abilities.
The truth probably lies somewhere in between. What’s clear is that:
- They’re not conscious or sentient
- They don’t have goals, desires, or experiences
- They can still be incredibly useful tools
The Hallucination Problem: The #1 Limitation You Must Understand
This is the single most important limitation to internalize. LLMs sometimes generate information that sounds completely plausible but is entirely made up. This is called “hallucination.”
My Wake-Up Call
I learned this the hard way early on. I asked an AI to provide academic citations for a research topic. It gave me:
“According to Smith et al. (2019) in the Journal of Cognitive Science, vol 43, pp. 112-128, the study found that…”
Beautiful. Specific. Authoritative. And completely fabricated. The author didn’t exist. The journal volume didn’t exist. The DOI led nowhere.
Why Hallucinations Happen
LLMs are trained to generate plausible text, not true text. They’re optimizing for “sounds like something a human would say,” not “is factually correct.”
When they don’t know something, they don’t say “I don’t know.” Instead, they generate what sounds like it could be correct based on patterns. It’s the equivalent of a very confident person who hates admitting uncertainty.
Types of Hallucinations
| Type | Example | Danger Level |
|---|---|---|
| Fabricated facts | Invented statistics, fake quotes | 🔴 High |
| Non-existent sources | Fake citations, imaginary books | 🔴 High |
| Plausible but wrong | Incorrect dates, mixed-up names | 🟡 Medium |
| Outdated information | Pre-training cutoff issues | 🟡 Medium |
| Confident uncertainty | Stating guesses as facts | 🟡 Medium |
How to Protect Yourself
-
Never trust without verification for anything consequential
- Medical, legal, financial information → verify with professionals
- Citations → check the actual sources exist
- Statistics → find the original data
-
Ask for sources - Even if they might be wrong, you can verify
-
Cross-reference - Use multiple LLMs or traditional search
-
Watch for red flags:
- Extremely specific details (exact page numbers, precise statistics)
- Obscure sources you’ve never heard of
- Information that seems too convenient
-
Use the right tool:
- For facts: Perplexity (cites real sources)
- For current events: Bing Chat, Google Gemini with search
- For research: Use LLMs to synthesize, but verify with primary sources
🎯 My Rule: Treat LLMs like a very smart colleague who sometimes confidently makes things up. You’d appreciate their ideas and drafts, but you’d always double-check critical facts before acting on them.
Are LLMs Actually Intelligent?
This is the million-dollar philosophical question. Here’s my take:
What they can do that feels intelligent:
- Understand nuance, context, and subtext
- Reason through multi-step problems
- Transfer knowledge across domains
- Engage in creative, open-ended tasks
- Explain their reasoning (sort of)
What they can’t do that suggests they’re not “truly” intelligent:
- Learn from a conversation (no persistent memory)
- Have genuine beliefs or preferences
- Experience the world
- Understand causation vs. correlation deeply
- Generalize beyond their training in novel ways
My conclusion: They’re the most sophisticated pattern-matching and text-generation systems ever created. Whether that constitutes “intelligence” depends on how you define the term. For practical purposes, it doesn’t matter—what matters is using them effectively.
Meet the Major LLMs (December 2025)
Let me introduce you to the main players. Each has its own personality and strengths.
OpenAI (GPT-5.2, o3)
The most well-known, powering ChatGPT. The GPT-5.2 family (released December 2025) comes in three flavors:
- Instant - Fast responses for quick tasks
- Thinking - Takes more time, better reasoning
- Pro - Maximum capability for complex work
They also have o3/o3-Pro, reasoning models that “think” step-by-step before responding. Great for math, science, and coding challenges.
Best for: General use, huge ecosystem, constantly improving
Anthropic (Claude Opus 4.5)
My personal favorite for long-form writing and nuanced conversations. Claude feels more… thoughtful? It’s hard to explain, but conversations feel more natural.
The Claude 4.5 family:
- Opus 4.5 - Flagship, world’s best coding model (Nov 2025)
- Sonnet 4.5 - Best balance of speed and smarts
- Haiku 4.5 - Fast and affordable
Best for: Writing, long documents (200K context), coding, nuanced tasks
Google (Gemini 3 Pro)
Google’s contender, with the biggest context window (1M+ tokens) and native multimodal capabilities—it natively processes text, images, audio, and video.
The Deep Research Agent (Dec 2025) can autonomously research topics and compile reports.
Best for: Working with large documents, multimodal tasks, Google ecosystem users
Meta (LLaMA 4)
The open-source champion. You can download and run LLaMA 4 on your own computer—no API, no monthly fees, complete privacy.
Variants:
- Scout - Efficient, smaller model
- Maverick - Full power
Best for: Privacy-conscious users, developers who want to customize, people who don’t want to pay monthly fees
DeepSeek (V3)
The rising star from China that’s been making waves globally. DeepSeek V3 offers impressive performance at a fraction of the cost of Western models. Their open-weight approach has made them popular with developers.
Key features:
- DeepSeek-V3 - Near GPT-4 level, incredibly cost-effective
- DeepSeek-Coder - Specialized for programming
- Open weights - Download and run locally
Best for: Cost-conscious users, developers, those who want open-weight models
Alibaba (Qwen 2.5)
Alibaba’s flagship LLM series, one of the best open-source models available. Qwen 2.5 performs competitively with GPT-4 on many benchmarks and comes in sizes from 0.5B to 72B parameters.
The family includes:
- Qwen-Max - Flagship API model
- Qwen 2.5-72B - Largest open model
- Qwen-Coder - Optimized for coding tasks
Best for: Open-source enthusiasts, multilingual tasks (excellent Chinese), developers
Moonshot AI (Kimi)
Kimi gained fame for its massive 200K+ token context window, one of the first to support reading entire books in one prompt. Popular in China for document processing.
Strengths:
- Extremely long context (up to 2M tokens claimed)
- Strong at document analysis and summarization
- Available through Moonshot API
Best for: Processing very long documents, Chinese language tasks, document analysis
MiniMax (ABAB 6.5)
One of China’s top AI unicorns, MiniMax has developed strong multimodal capabilities including text, voice, and video generation through their Hailuo platform.
Features:
- Text, voice, and video AI in one platform
- Strong creative content generation
- Competitive pricing for API access
Best for: Multimodal content creation, voice synthesis, Chinese market applications
Quick Comparison
| Model | Best For | Context | Price | Open Source |
|---|---|---|---|---|
| GPT-5.2 Pro | Professional work | 256K | $$ | No |
| o3-Pro | Complex reasoning | 128K | $$$ | No |
| Claude Opus 4.5 | Coding, long docs | 200K | $$ | No |
| Gemini 3 Pro | Multimodal, research | 1M+ | $$ | No |
| LLaMA 4 | Privacy, customization | 128K | Free | Yes |
| DeepSeek V3 | Cost-effective, coding | 128K | $ | Open-weight |
| Qwen 2.5 | Open-source, multilingual | 128K | Free | Yes |
| Kimi | Very long documents | 200K+ | $$ | No |
| MiniMax ABAB | Multimodal, Chinese | 32K | $$ | No |
For a deeper look at how these models compare across different capabilities, check out this interactive comparison:
LLM Capability Comparison
Illustrative comparison based on public benchmarks
Sources: MMLU Benchmark • HumanEval • Chatbot Arena
Getting Started: Your First Steps
Ready to try this yourself? Here’s how I’d recommend getting started:
Free Options (No Credit Card Needed)
- ChatGPT - chat.openai.com - The most popular, free tier available
- Claude - claude.ai - My recommendation for beginners
- Gemini - gemini.google.com - Free with Google account
- Perplexity - perplexity.ai - Great for research, includes citations
- DeepSeek - chat.deepseek.com - Excellent for coding, generous free tier
- Kimi - kimi.moonshot.cn - Long context for documents (Chinese-focused)
Tips for Better Results
After months of daily use, here’s what I’ve learned:
Be specific. Instead of “Write me an email,” try “Write a professional but friendly email to a client explaining that their project will be delayed by two weeks due to supply chain issues. Include an apology and a new timeline.”
Provide context. Tell the AI who you are, who you’re writing for, and what tone you want.
Ask for the format you want. “Give me bullet points,” “Use markdown headers,” “Structure this as a table.”
Iterate. Your first response probably won’t be perfect. Ask for revisions: “Make it shorter,” “More casual tone,” “Add more specific examples.”
Use roles. “You are an expert copywriter…” or “Pretend you’re a patient teacher explaining to a beginner…”
Starter Projects to Try
- Summarize a long article (paste it in, ask for key points)
- Get help with an email you’ve been putting off
- Ask it to explain a concept you’ve never understood
- Brainstorm ideas for a project
- Debug a piece of code that’s not working
- Translate something and ask it to explain the nuances
The Important Truth: These Aren’t Magic
I want to end with something I wish someone had told me earlier: LLMs are tools, not oracles.
They’re incredibly useful tools—probably the most significant productivity boost I’ve experienced since smartphones. But they’re not infallible. They don’t actually “know” things the way humans do. They’re pattern-matching machines that have learned very, very good patterns.
Use them to:
- Speed up work you already know how to do
- Explore ideas and possibilities
- Draft content you’ll refine yourself
- Learn concepts faster (but verify with authoritative sources)
- Automate tedious tasks
Don’t use them to:
- Replace your own judgment on important decisions
- Trust for medical, legal, or financial advice
- Cite as a primary source without verification
- Generate content you won’t review
With those caveats in mind, I genuinely believe LLMs are one of the most transformative technologies of our time. Understanding how they work—even at this high level—makes you a more effective user and a more informed citizen in an AI-shaped world.
The numbers back this up. The AI market is experiencing explosive growth, and LLMs are driving a significant portion of it:
The AI Market Explosion
Projected to reach $1.8+ trillion by 2030
$280B
2024 Market
$390B
2025 Est.
$1.8T+
2030 Projected
Sources: Fortune Business Insights • Statista • McKinsey
What’s Next?
This is just the beginning. In the next article, we’ll explore The Evolution of AI—From Rule-Based Systems to GPT-5, tracing the fascinating journey from 1950s chess programs to today’s multimodal marvels.
Ready to go deeper? Here’s my suggested learning path:
- ✅ You are here: What Are Large Language Models?
- 📖 Next: The Evolution of AI
- 📖 Then: How LLMs Are Trained
- 📖 Then: Prompt Engineering Fundamentals
Key Takeaways
Let’s wrap up with the essential points:
- LLMs are language prediction systems scaled to billions of parameters
- They learn patterns, not facts—expect occasional errors
- AI → ML → Deep Learning → LLMs—each is a subset of the one before
- Training happens in three stages: pre-training, fine-tuning, and RLHF
- Key concepts: tokens (text chunks), context window (working memory), parameters (brain size)
- They excel at writing, coding, explaining, brainstorming
- They struggle with math, real-time info, and factual accuracy
- Always verify important outputs—hallucinations are real
Now go try one out. Ask it to explain something you’ve always wondered about. Or get help with that email you’ve been dreading. The best way to understand LLMs is to use them.
Related Articles: